
1、Product Overview
The Unified Data Development Platform is the output source of the data platform capabilities, and it is a group of data agile development tools. The data development platform conforms to the business and technical characteristics of colleges and universities, complies with the concept of full data link management, and enables data governance and data application. The unified data development platform supports seamless connection with various components of the midrange platform and realizes the agile development mode of ‘design’ is ‘development’ and ‘what you see’ is ‘what you get’ driven by metadata intelligence. In essence, it shortens the data value reflection cycle and improves the efficiency of data value development.
2、Product Functions


The main functions of the unified data development platform include:
- Data Integration
The data integration tool is a concise integration platform based on the web. It supports the connection with unified identity authentication, and the seamless connection with the information standards, metadata, and data lineage of the data governance platform. The integration interface can display Chinese semantic descriptions according to metadata settings, greatly reducing the technical barriers to data integration. It supports online data integration and exchange of various common big data, relational data, API interface data, text data, message data and unstructured data. The development and customization of all data integration interfaces are realized by dragging on the web site without coding. It can be deployed in the campus private cloud or internal data center and provides online data integration services through unified browser access. Users do not need to install any plug-ins or clients locally.
Taking full account of the characteristics of the colleges and universities industry, the tool supports data replication and table creation, batch generation interface, two-way synchronization with the data governance platform, batch generation of data interface, and automatic construction of data field mapping by artificial intelligence, which greatly reduces the time cost and operation and maintenance cost of data exchange.
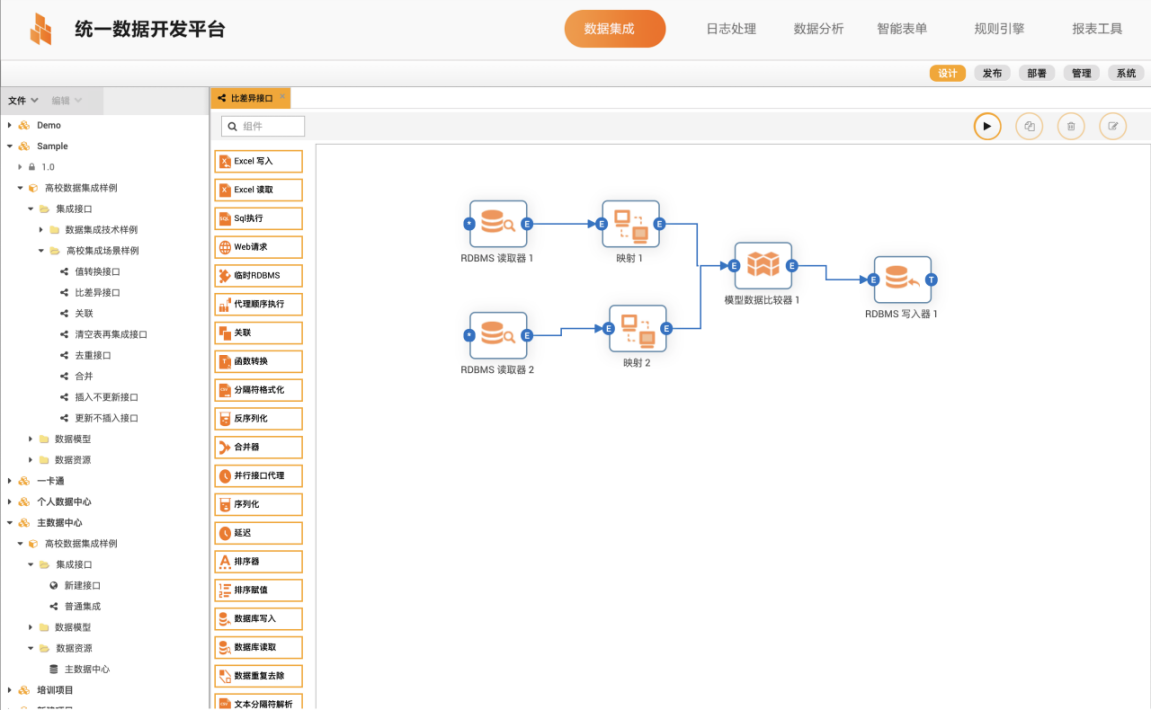
The data integration tool automatically records all integration processes and data operations and provides data kinship and data impact analysis data for the data governance platform and foreground data applications.
- Log Processing
The log processing tool is a one-stop log processing tool based on Hadoop、ElasticSearch、ClickHouse distributed storage. It collects logs generated by different log sources (including Windows systems, Unix/Linux systems, applications, routers, firewalls, etc.), realizes centralized and unified management and storage of logs, and has the ability of real-time retrieval, query analysis, and alarm monitoring. It also provides a computing engine (flow computing, batch computing) to further process the data.
As a unified log processing center, it centrally processes all kinds of streaming unstructured log information in colleges and universities. These data can come from any place that can generate logs, such as log information collected by network probes, device log information, log information generated by application servers, etc. relevant personnel can retrieve and analyze these logs, to locate problems faster and continuously mine data value.
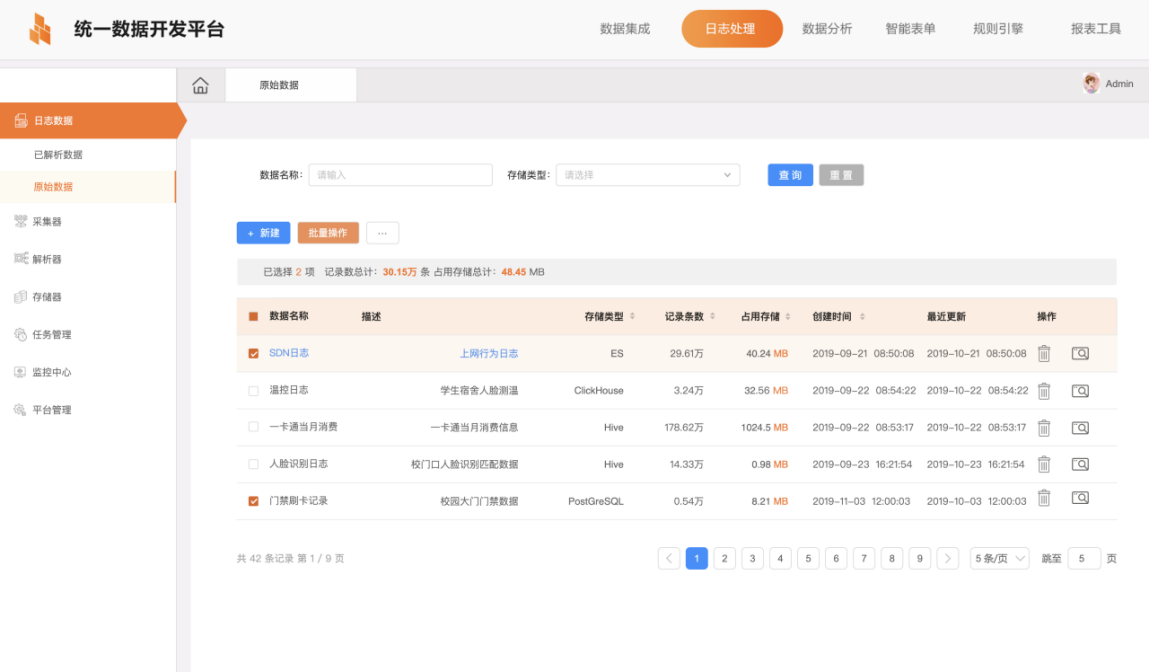
For the collected logs, the tool can reference the corresponding data analysis template to perform secondary calculation on the data and realize the value output of the log data by setting different warning rules. For example, the access control log, all-in-one card consumption log and flow control log can be used to locate the students who may not be in school, and the log can be used to analyze the relationship between students and loneliness index.
The log processing is completed based on the distributed system, which can automatically associate with the relational database to realize the real name and business requirements. The log can provide fast and real-time calculation and result output based on memory, support the front-end log search, seamlessly connect with the data analysis component, support the custom output of log related reports and charts, and realize the unified visual output of data assets.
- Intelligent Filling
The construction of intelligent filling tool will take ‘service’ as the main theme, quickly build the form data filling service in the school based on the global data center, and quickly build the passive information collection business around objects (teachers, students, assets). By replacing multiple application forms and materials for a single or multiple approval items with ‘one form’, and by means of ‘automatic data filling + form flow approval’, the information service mode of ‘one form for all kinds of items and business handling applications’ and ‘more data running, less teachers and students running errands’ is realized.
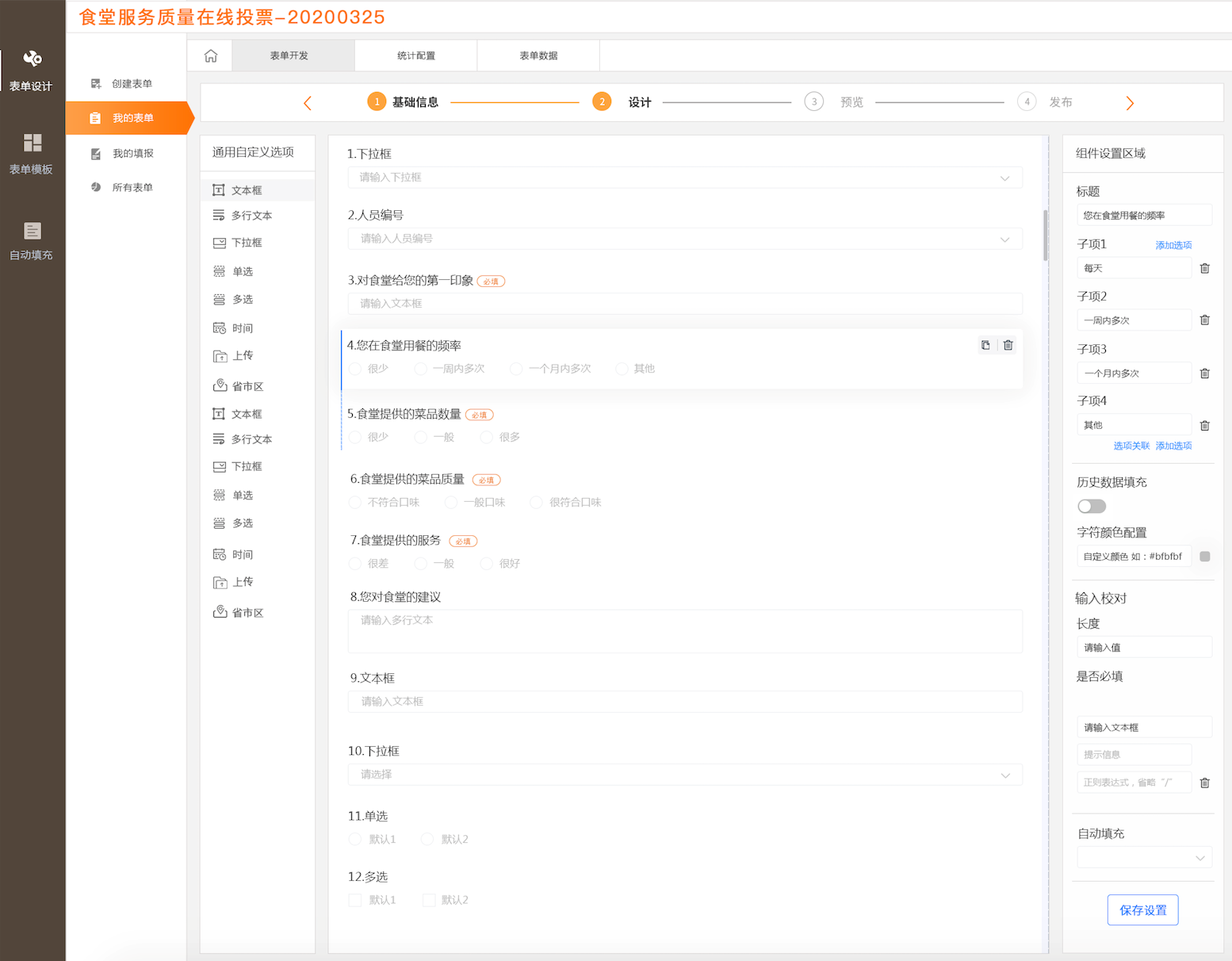
The intelligent filling tool adopts a lightweight mobile system for system construction. It can quickly customize various general forms (such as health punch in, online research, activity registration, etc.) and business reports (Faculty Title declaration, teacher post-employment, year-end work assessment, etc.) through a visual interface. The client can quickly realize self-service report filling and solve the problem of filling in existing information repeatedly. It can be seamlessly connected with school identity authentication, WeChat enterprise number, WeLink number, Dingding, and other platforms to achieve real name filling.
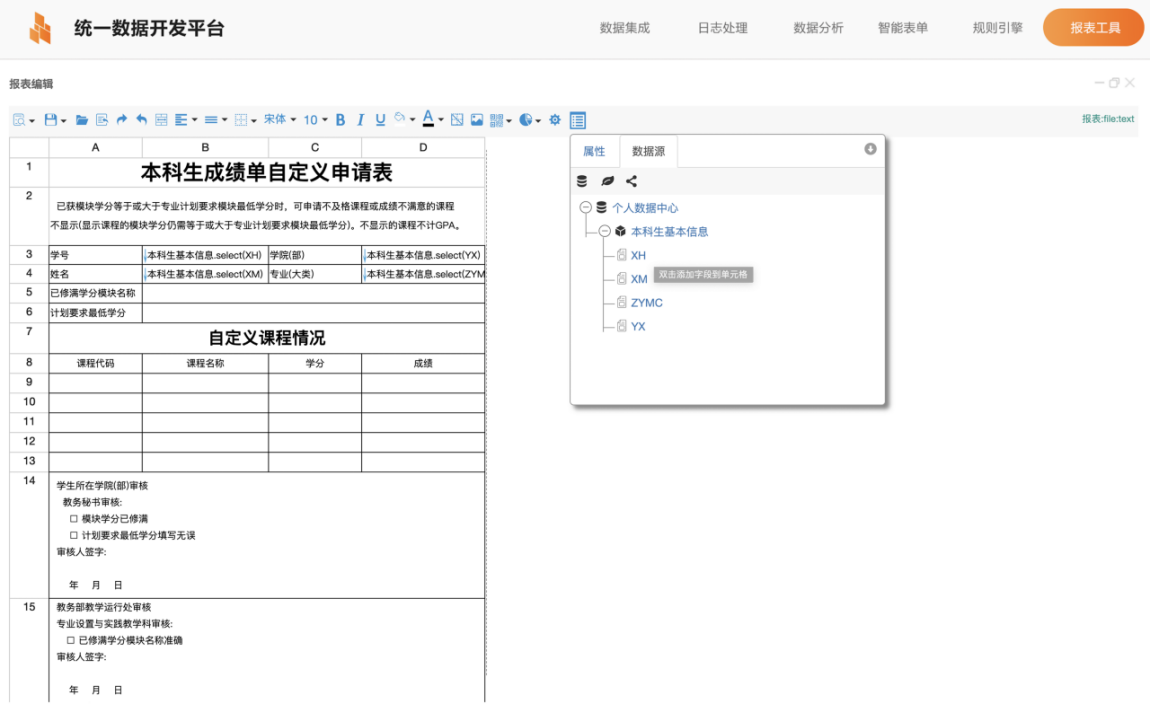
In short, the online agile development capability of the report tool can provide a one-stop data report designer for management departments or business executives, support the continuous construction of reports, and provide automated report services for teachers and students. The report provides historical form filling version management, records the filling history, improves the filling cycle, and adopts a data-oriented and content-oriented construction method to ensure that the data is not lost and continuous.
- Data Analysis
The data analysis tool provides the ability of various online data visualization and agile development, quickly constructs data query and data analysis topics, and provides the ability of ad hoc analysis, data large screen analysis, data analysis report output, etc. In terms of data analysis capability, it can meet the access of mobile terminals such as mobile phones and PAD and large screen visualization. It can provide leadership cockpit functions by classification and provide support for business decisions of different leaders in their areas of responsibility. It supports various mainstream, commonly used and customized data visualization components, including bubble cloud, Sankey diagram, funnel plots, national map, Nightingale rose diagram, GIS regional map, rectangular tree diagram, Sector Graph, focus information map, TOP bar chart, relationship chart and other vivid and rich display forms, and supports one click switching of graphics.
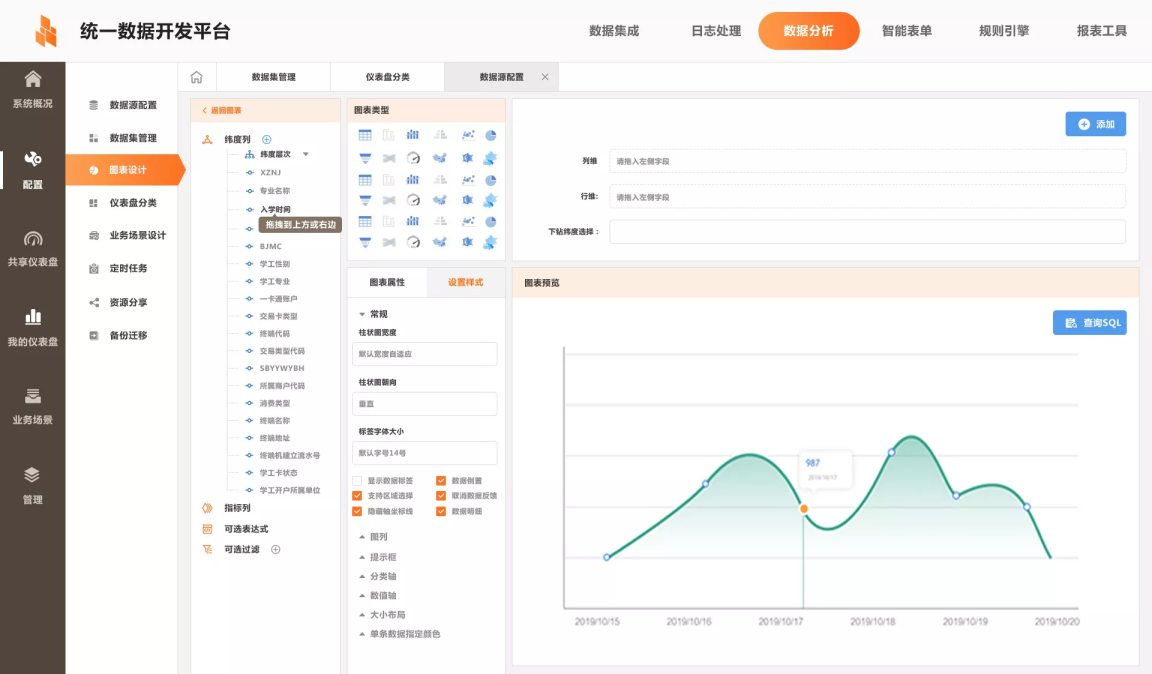
- Rule Engine
Rule engine is a colleges and universities general data computing platform independently developed based on the underlying big data distributed computing framework according to the characteristics of colleges and universities big data applications. The rule engine can realize the rapid calculation of school level indicators, form a school level KPI library, provide customization of personal KPI library for personal data, provide personalized and dynamic label computing capabilities, and meet the growing data label demand of big data analysis. Provide various data quality inspection rules for the database to form a standardized rule interface for use by other business systems in the school. Based on the standard data mining algorithms (time series, regression, Kmeans, etc.) and in combination with the industry characteristics of colleges and universities, the tool can form campus customized algorithms such as academic early warning, poor student early warning, false poverty early warning, out of school early warning, etc.
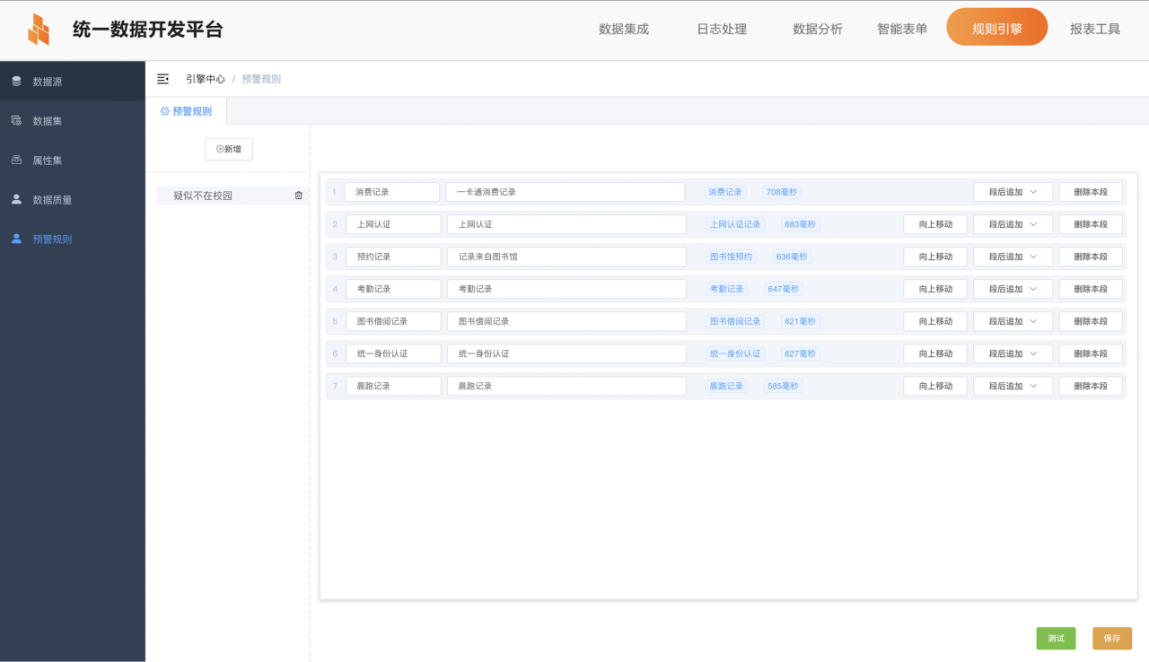
3、Product Features
The biggest advantages of the unified data development platform over the traditional data development middleware are:
- All capabilities converge in an independent and complete private cloud system with high development efficiency.
- It supports distributed deployment, runs stably, and performs extremely well under the scenario verification of nearly 100 colleges and universities.
- All module development does not require secondary modeling and can be seamlessly connected with the metadata and information standards of the data governance platform, greatly improving the data specification and operation consistency.
- Based on the architecture of full data link, it realizes automatic data traceability of all development achievements, automatic docking data quality feedback, automatic matching of related historical data, automatic impact analysis, and full-time link monitoring without dead corners.
- All modules can be seamlessly connected with the cloud knowledge base, which can provide each school with many materials for data governance, data opening, data development and data application, essentially reducing the difficulty of tool landing and getting started.